

Introduction
As technology evolves, so do the methodologies and tools employed in software development. The emergence of Artificial Intelligence (AI), specifically Large Language Models (LLM) has revolutionized the way we approach various tasks, including code writing. This whitepaper explores the potential of Language Models, specifically Large Language Models (LLMs), and AI in code development and the implications it has on traditional security assessments. Specifically, it aims to discuss whether the use of LLMs and AI negates the necessity for Static Application Security Testing (SAST) and Dynamic Application Security Testing (DAST).
Summary
This whitepaper outlines the advantages and challenges associated with employing LLMs/AI in code development. It examines the traditional role of SAST/DAST in security assessments and explores the potential for LLMs to enhance security assurance. While LLMs offer benefits such as code quality improvement and vulnerability reduction, concerns regarding adversarial attacks and the need for ongoing monitoring are also discussed. Ultimately, we conclude that while LLMs and AI have the potential to reduce reliance on traditional security assessments, they should be considered as complementary tools rather than replacements.
Understanding Language Models and AI in Code Development
Language Models(LMs), powered by Artificial Intelligence (AI), have become powerful and almost indispensable tools in code development within the past year. These systems, like GPT-3.5 and GPT-4, are trained on vast amounts of existing code and programming documentation, enabling them to generate human-like text and code snippets. In the context of code development, Language Models excel at automating tasks, providing code suggestions, and assisting developers in writing mostly syntactically correct code. By analyzing patterns and structures in the training data, Language Models learn to mimic programming styles and can offer valuable insights and recommendations to enhance code quality and productivity. With their ability to process and generate code, Language Models have revolutionized the way developers approach programming tasks, empowering them to build software faster and with improved efficiency.
Code completion tools, such as Copilot, leverage LMs to offer contextual suggestions as developers write code, enhancing productivity and reducing errors. Code generation tools allow developers to express their intentions in natural language, which the LMs translate into functioning code, streamlining development. Code review tools analyze code snippets using LMs, providing suggestions for improvement and identifying potential issues, including adherence to coding standards and security best practices. Documentation generation tools employ LMs to automatically generate up-to-date code documentation, saving time and ensuring consistency.
In summary, LMs, as a subset of AI, has changed code development through automation, suggestions, and improved productivity. They enable a new generation of coding tools that assist developers in various aspects of the development process.
The Role of SAST and DAST in Traditional Security Assessments
SAST (Static Application Security Testing) and DAST (Dynamic Application Security Testing) play critical roles in traditional security assessments. SAST focuses on analyzing the application’s source code and static components to detect vulnerabilities early in the development phase. It scans for coding errors, insecure practices, and known weaknesses. DAST, on the other hand, evaluates the application’s security from an external perspective while it is running. By simulating real-world attacks, DAST identifies vulnerabilities such as injection attacks and XSS by interacting with the application’s interfaces. The combination of SAST and DAST provides a comprehensive approach to vulnerability detection, ensuring the resilience and security of software applications.
It’s important to note that while SAST and DAST are valuable testing techniques, they have their limitations. SAST may produce false positives and false negatives, requiring manual verification, and it may not capture vulnerabilities introduced by external dependencies. DAST, although effective at simulating attacks, may not have visibility into the application’s internal code. Therefore, a holistic approach that incorporates both SAST and DAST, along with other security measures such as penetration testing and secure coding practices, is recommended to achieve a robust and comprehensive security assessment.
The Potential of Language Models in Security Assurance
Large language models(LLMs) offer significant potential for improving security assurance in development. In theory by leveraging the knowledge stored in their vast training data, LLMs can detect common security vulnerabilities and generate more secure code snippets. They can also provide feedback to developers, ensuring adherence to secure coding practices and standards. Additionally, LLMs can learn from security-related datasets, contributing to continuous improvement in code security.
The potential of Language Models (LMs) in security assurance is significant, offering opportunities to enhance code quality, reduce vulnerabilities, and improve overall software security. LMs, such as GPT-3.5, trained on vast amounts of code and programming knowledge, can analyze and generate code snippets, making them valuable tools in security assessments.
One aspect of the potential lies in the ability of LMs to detect common security vulnerabilities. By leveraging training data, LMs can identify coding patterns and structures that are associated with vulnerabilities such as SQL injection, cross-site scripting (XSS), or buffer overflows. LMs can assist developers by suggesting secure alternatives or pointing out potential weaknesses in the code, helping to prevent vulnerabilities at an early stage.
LMs can aid in promoting adherence to secure coding practices and standards. They can provide real-time feedback to developers, highlighting potential security issues and guiding them towards writing more secure code. This not only improves code quality but also cultivates a security-conscious mindset among developers, leading to a stronger security posture across the development lifecycle.
Additionally, LMs have the capacity to learn from security-related datasets, enabling continuous improvement in security assurance. By training LMs on data that encompasses known vulnerabilities, threat intelligence, and security best practices, they can gain a deeper understanding of security considerations. This knowledge can then be utilized to provide more accurate and context-aware security suggestions during code development.
In conclusion, LMs hold immense potential in enhancing security assurance. Their ability to detect vulnerabilities, guide developers towards secure coding practices, and learn from security-related datasets can significantly contribute to the overall security posture of software applications. While LMs are not a standalone solution, they can serve as valuable tools in conjunction with traditional security assessments, creating a more robust and effective security assurance process.
Addressing Concerns and Challenges
While Language Models (LMs) offer a potential improvement in security assurance, it is crucial to address the concerns and challenges associated with their usage to ensure their effective and secure implementation. One primary concern is the possibility of LMs generating code containing vulnerabilities or malicious patterns. Adversarial attacks can exploit LMs’ vulnerabilities to produce code with hidden security flaws. To address this, LM generated code should always be scrutinized, and ongoing monitoring and validation is essential. Combining LMs with traditional security assessments, such as static and dynamic analysis, can help identify and mitigate any vulnerabilities introduced by the LMs themselves.
Another challenge is the need for continuous training and updating of LMs to stay abreast of the evolving threat landscape. As new threats arise, LMs will not be able to generate code that avoid introducing those threats into code, until they are presented with enough data and training. Traditional SAST/DAST scans may also suffer from this issue; however, they tend to be updated much more frequently. It is also important to note that LM may be biased based upon the data it was trained on. This bias in training data can lead to biased code suggestions, potentially impacting security considerations.
Interpreting the output of LMs can also be challenging, as they may generate code that appears correct on the surface but contains subtle vulnerabilities. Developers and security practitioners need to be aware of this and exercise judgment when incorporating LM-generated code into their applications.
Lastly, one important aspect to consider is that LMs lack the full context of a development project, which introduces inherent risks. While LMs have been trained on vast amounts of code and programming knowledge, they do not possess knowledge of project-specific intricacies, business requirements, or the specific security considerations unique to each application. This limited context can lead to misunderstandings or oversights in the suggestions or code generated by LMs. It is crucial for developers to exercise caution and not rely solely on LM-generated output without considering the project-specific factors and engaging in comprehensive code review and testing processes. The risk associated with this limited context underscores the importance of human involvement and expertise in security assessments, ensuring that critical project-specific nuances are accounted for, and potential vulnerabilities are properly addressed.
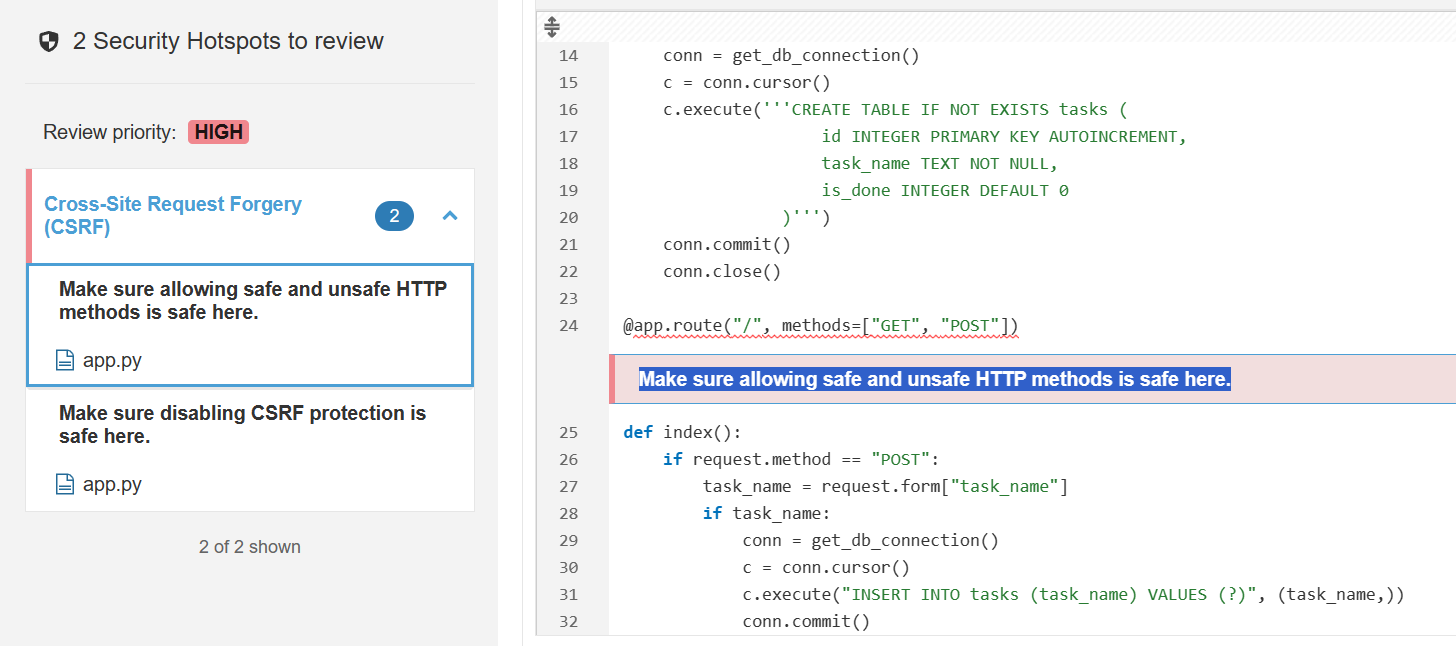
SAST Example
In our testing we asked ChatGPT to create a ToDo List application using Flask as the web framework and SQLite for the database. We then performed a SAST scan against the written code. The end results were that there were a few security concerns around a few CSRF vulnerabilities. It should be noted that the SAST scanner used, SonarCube, considers the issues to be “Minor”. You can find more information on the security hotspot here. It should be noted while creating a ToDo is a relatively simple project, it is assumed that a more complex project may introduce more vulnerabilities.
Conclusion
To conclude, the integration of Language Models (LLMs) and AI in code development presents opportunities to enhance code quality and security. However, it is important to recognize that LLMs should not be viewed as complete replacements for traditional security assessments like SAST and DAST. Instead, a practical and effective approach is to adopt the principle of security in depth. By combining the strengths of LLMs with SAST, DAST, and formal penetration testing, organizations can maximize their ability to identify and address potential code flaws comprehensively. This multi-layered approach ensures a more robust and resilient security posture, leveraging the unique capabilities of LLMs while utilizing established security assessment practices. By embracing this holistic approach, developers can leverage the potential of LLMs while benefiting from the expertise and thoroughness provided by traditional security assessments.